
Dataset
All datasets consist of files - every file is a recording of one trial. During the trial a person entered a PIN number by clicking with a mouse a sequence of digits displayed on the screen. Both mouse and eye positions were registered during the trial.
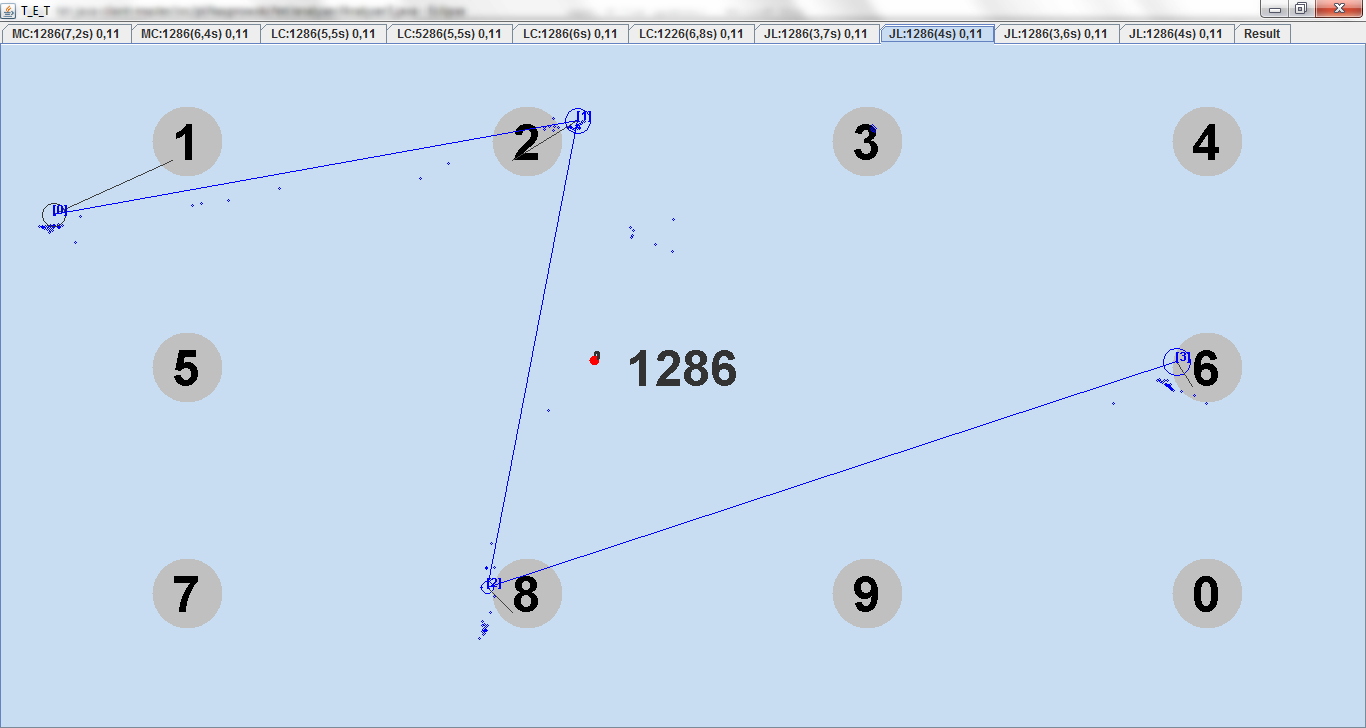
To enable comparisons every person entered exactly the same PIN number "1286" as it is visible in the figure.
Each file is in TSV format and each line in the file consists of four values:
timestamp type x y
- timestamp is the number of miliseconds from the start of the trial
- type is the type of the recording:
- M for mouse position
- G for gaze position
- MC for mouse click position (there are exactly 4 mouse clicks in each trial)
- x and y are screen coordinates of mouse/gaze/mouse click accordingly.
The trials in the dataset are divided into labeled and unlabeled. The labeled trials are stored in /labeled
folder and each file name has the following format:
lac_[fileId]_[no]_[subjectId]
The unlabeled trials are stored in /unlabeled folder and each file name has the following format:
lac_[fileId]_[no]_sXXX
Every subject took part in two sessions separated by at least a week and there were three trials recorded during each session,
saved as separate files with numbers 0, 1, 2 (field [no]).
Trials recorded during the first session are the labeled trials (/labeled folder) and trials recorded during the second session
are the unlabeled ones (/unlabeled folder).
The task for participants is to predict correct labels (subject ids) for unlabeled trials using information obtained from the labeled ones.
The first dataset is a sample dataset. It consists of 30 trials recorded by 5 participants.
Additionally, because it is a sample dataset, a key is available in file key.txt.
The key is in the same format as it will be required for the competition dataset. See Competition formula for details.
Please register (using Registration link) and you should be able to download the datasets from here.